One of my few, and not very compelling, claims to fame is a (still unpublished) paper (“The Fisher Effect Under Deflationary Expectations“) that I wrote in late 2010 in which I used the Fisher Equation relating the real and nominal rates of interest via the expected rate of inflation to explain what happens in a financial panic. I pointed out that the usual understanding that the nominal rate of interest and the expected rate of inflation move in the same direction, and possibly even by the same amount, cannot be valid when the expected rate of inflation is negative and the real rate is less than expected deflation. In those perilous conditions, the normal equilibrating process, by which the nominal rate adjusts to reflect changes in inflation expectations, becomes inoperative, because the nominal rate gets stuck at zero. In that unstable environment, the only avenue for adjustment is in the market for assets. In particular, when the expected yield from holding money (the expected rate of deflation) approaches or exceeds the expected yield on real capital, asset prices crash as asset owners all try to sell at the same time, the crash continuing until the expected yield on holding assets is no longer less than the expected yield from holding money. Of course, even that adjustment mechanism will restore an equilibrium only if the economy does not collapse entirely before a new equilibrium of asset prices and expected yields can be attained, a contingency not necessarily as unlikely as one might hope.
I therefore hypothesized that while there is not much reason, in a well-behaved economy, for asset prices to be very sensitive to changes in expected inflation, when expected inflation approaches, or exceeds, the expected return on capital assets (the real rate of interest), changes in expected inflation are likely to have large effects on asset values. This possibility that the relationship between expected inflation and asset prices could differ depending on the prevalent macroeconomic environment suggested an empirical study of the relationship between expected inflation (as approximated by the TIPS spread on 10-year Treasuries) and the S&P 500 stock index. My results were fairly remarkable, showing that, since early 2008 (just after the start of the downturn in late 2007), there was a consistently strong positive correlation between expected inflation and the S&P 500. However, from 2003 to 2008, no statistically significant correlation between expected inflation and asset prices showed up in the data.
Ever since then, I have used this study (and subsequent informal follow-ups that have consistently generated similar results) as the basis for my oft-repeated claim that the stock market loves inflation. But now, guess what? The correlation between inflation expectations and the S&P 500 has recently vanished. The first of the two attached charts plots both expected inflation, as measured by the 10-year TIPS spread, and the S&P 500 (normalized to 1 on March 2, 2009). It is obvious that two series are highly correlated. However, you can see that over the last few months it looks as if the correlation has been reversed, with inflation expectations falling even as the S&P 500 has been regularly reaching new all-time highs.
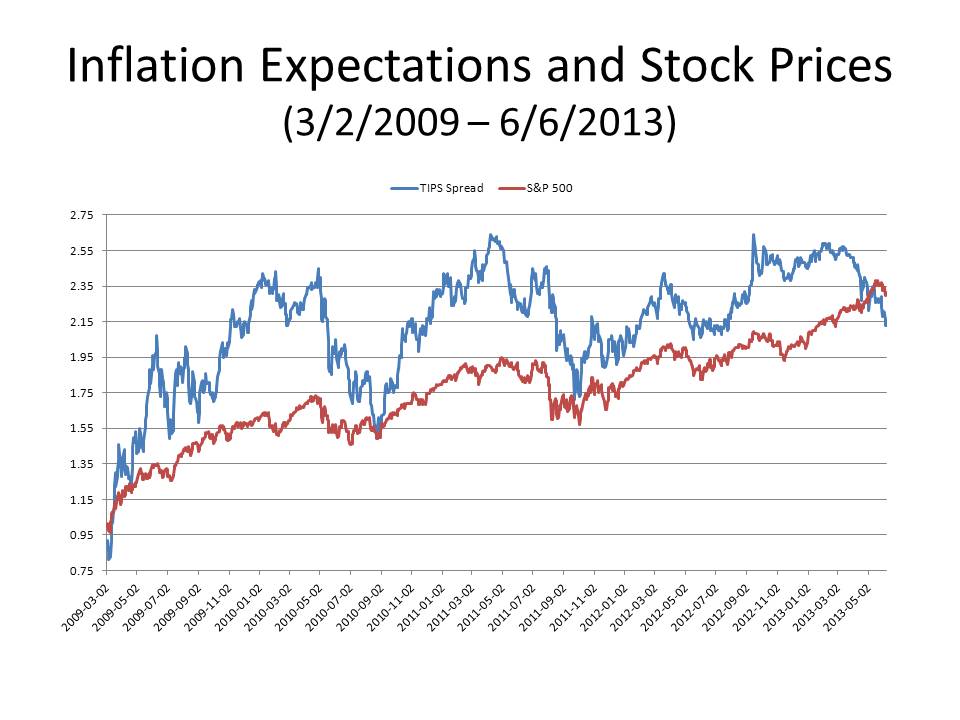
Here is a second chart that provides a closer look at the behavior of the S&P 500 and the TIPS spread since the beginning of March.
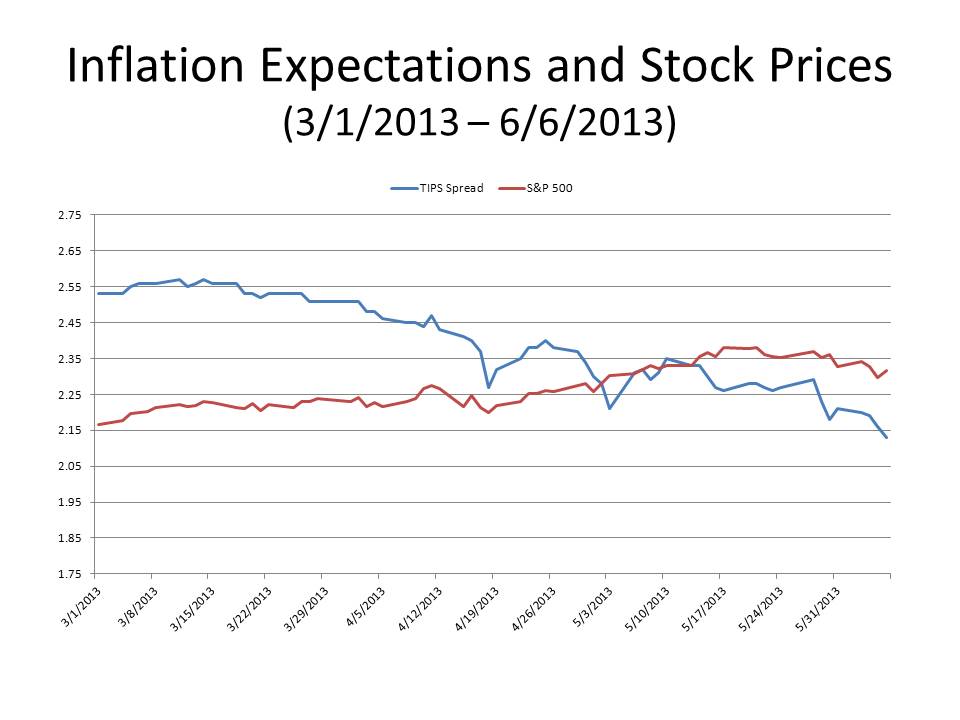
So what’s going on? I wish I knew. But here is one possibility. Maybe the economy is finally emerging from its malaise, and, after four years of an almost imperceptible recovery, perhaps the overall economic outlook has improved enough so that, even if we haven’t yet returned to normalcy, we are at least within shouting distance of it. If so, maybe asset prices are no longer as sensitive to inflation expectations as they were from 2008 to 2012. But then the natural question becomes: what caused the economy to reach a kind of tipping point into normalcy in March? I just don’t know.
And if we really are back to normal, then why is the real rate implied by the TIPS negative? True, the TIPS yield is not really the real rate in the Fisher equation, but a negative yield on a 10-year TIPS does not strike me as characteristic of a normal state of affairs. Nevertheless, the real yield on the 10-year TIPS has risen by about 50 basis points since March and by 75 basis points since December, so something noteworthy seems to have happened. And a fairly sharp rise in real rates suggests that recent increases in stock prices have been associated with expectations of increasing real cash flows and a strengthening economy. Increasing optimism about real economic growth, given that there has been no real change in monetary policy since last September when QE3 was announced, may themselves have contributed to declining inflation expectations.
What does this mean for policy? The empirical correlation between inflation expectations and asset prices is subject to an identification problem. Just because recent developments may have caused the observed correlation between inflation expectations and stock prices to disappear, one can’t conclude that, in the “true” structural model, the effect of a monetary policy that raised inflation expectations would not be to raise asset prices. The current semi-normal is not necessarily a true normal.
So my cautionary message is: Don’t use the recent disappearance of the correlation between inflation expectations and asset prices to conclude that it’s safe to abandon QE.

Fascinating stuff, Mr. Glasner!
Haven’t phenomenal new oil discoveries been made lately in the U.S.? Shouldn’t a huge positive supply shock like that simultaneously increase the real expected return for U.S. businesses (lower COGS) and put downward pressure on inflation expectations at the same time?
LikeLike
Interesting stuff, but I wonder if perhaps the change in correlation is due to the possibility that the TIPS spread is an imperfect measure of inflation. Using Cleveland Fed data (http://www.clevelandfed.org/research/data/inflation_expectations/) might suggest a different conclusion
LikeLike
David,
Simple answer: Housing prices (not included in CPI inflation) have bottomed out.
LikeLike
Frank,
Your theory seems doubtful. Shouldn’t a bottom in housing result in increased expectations of future core inflation?
LikeLike
TravisV,
Housing prices are not included in either headline or core CPI inflation. Instead owner’s equivalent rent is used. Owner’s equivalent rent is calculated based upon rental costs. And so if more people are buying houses and fewer are renting, that would put downward pressure on the CPI (the inflation component of TIPs).
LikeLike
Frank,
Whoops, thanks for setting me straight. I was thinking of some kind of positive wealth effect from higher home prices that motivates people to buy more stuff. But as you point out, that factor is probably outweighed by lower rental rates.
LikeLike
Speaking of that working paper on the Fisher Effect…I still think you might want to give reference to an article detailing the history behind it, David Glasner. In case you weren’t aware, Robert W. Dimand and Rebecca G. Betancourt had an article on the history behind the Fisher Effect published in an issue of the Journal of Economic Perspectives in 2010.
http://www.aeaweb.org/articles.php?doi=10.1257/jep.26.4.185
As for whether the American economy as a whole is finally making a solid and strong recovery (and not to mention the global economy at large)…it’s stil too early to say. While the stock market might genuinely be signalling a strong recovery, I can be overly cautious, and by the time I realise that the recovery in America is finally turning solid and for real, it shall be too late.
LikeLike
In those perilous conditions, the normal equilibrating process, by which the nominal rate adjusts to reflect changes in inflation expectations, becomes inoperative, because the nominal rate gets stuck at zero. In that unstable environment, the only avenue for adjustment is in the market for assets. In particular, when the expected yield from holding money (the expected rate of deflation) approaches or exceeds the expected yield on real capital, asset prices crash as asset owners all try to sell at the same time, the crash continuing until the expected yield on holding assets is no longer less than the expected yield from holding money. Of course, even that adjustment mechanism will restore an equilibrium only if the economy does not collapse entirely before a new equilibrium of asset prices and expected yields can be attained, a contingency not necessarily as unlikely as one might hope.–DG
Brilliant blogging. This is right!
But! That is why the Fed has to be very aggressive in pushing for growth now. It has to pour it on, and say it will pour it on, and then pour it on some more, and say it will pour it on some more. This could take years of QE.
Glasner explains why it may be dangerous to have such a low inflation target. At 2 percent, then comes along a recession, and we find ourselves at zero bound, and soon cash is worth holding, and all asset prices are plunging, and banks see their loans going sour and stop lending…I think it is called 2008. It is hard to be an alarmist when that actual scenario already happened…
I wonder if a 3 percent inflation target is better. Really, what is the peevish fixation on minute rates of inflation…I think you have to be a Phd economist to give a hoot whether inflation is at 3 percent or 2 percent…..
I find prosperity is a better life than monetary asceticism…..can we just have some boom times and Fat City?
LikeLike
George Selgin model say that you can have deflation and at the same time the economy doesn’t feel pain.
LikeLike
David,
You raise some good questions. The “rising optimism” explanation for real rates is congruent with recent stock market moves. However, that thesis fails to account for the last four years of rising stocks and falling real rates.
Further, there seems little actual evidence to support the “optimism” explanation. Global growth is slowing. The data in the U.S. has been decidedly mixed: We have better consumer sentiment, a slight pick up in job growth, and a housing bounce. These are offset by a sub-50 ISM, falling manufacturing employment, flat hours worked, flat durables orders YTD, etc. Indexes of “macro data surprises” have been consistently falling for months. We are focused on expectations, but clearly, nothing in the incoming data supports a dramatic change–a tipping point–in expectations versus the past four years of falling real rates.
Conclusion: The data does not fit with most broad economic theses regarding the real rate.
LikeLike
The answer seems obvious to me: both have been stoked by what’s happening in monetary policy and after all this time speculators have realized that QE doesn’t impact the stock market in any way other then effecting the expectations of the speculators themselves.
LikeLike